たまたまCRISP-DMという言葉に出会い、調べてみたらまさに膝を打つ思いがしました。
そもそも、CRISP-DM(たぶん、クリスプ ディーエム と読むのだと思います)とは何でしょう?
「Cross-industry standard process for data mining」の略で、いろんな業界にて標準的に活用できるデータ分析のプロセスです。
(出典:Wikipedia )
ここで説明されている、データを分析する際の6つのプロセスを見て「うわっ、普段自分が考えていることと全く重なる!しかも、きれいにまとめられている!」と思わず唸ってしまいました。
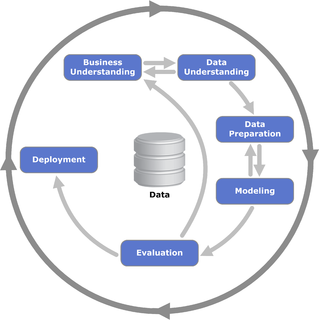
詳細につきましては、是非、出典元をお読みになっていただきたいのですが、自分なりに6つのプロセスを要約してみたいと思います。
1.Business Understanding
まず最初に重要なことは、そのデータを分析する目的、解決したい課題、そして仮設を十分に理解すること。
2.Data Understanding
分析するデータ自体の構造や内容を十分に理解します。いわゆる要約統計量、記述統計量といわれるものをまずはじっくり見ていきたいです。なお、データを触りながら、探索的にどんな分析をするか(できるか)を検討することもありますが、CRISP-DMの図でも、Business UnderstandingとData Understandingは双方向の矢印になっていますね。
3.Data Preparation
やりたいデータ分析ができる形にデータを整えます。最近では「前処理」「前加工」「Tidy data」などと呼ばれていると思います。地道な作業となりますが、データ分析の80%の時間を要すると言われることもある重要な工程です。
具体的には以下のような作業となります。
- 欠損値の処理
- 外れ値の処理
- テーブルどうしの結合
- カテゴリの導出 など
4.Modeling
データを使用して、回帰、分類、時系列などのモデル式を当てはめます。実際には、分析に使用するプログラム言語のライブラリを選ぶ工程となります。
5.Evaluation
構築したモデルの適合性を評価します。
6.Deployment
データ分析から得られたモデルや結果を実際の業務に落とし込みます。
今後も使える考え方
いかがでしょうか?まさに普段考えていること!と思われる方も多かったのではないでしょうか。
これからのデータマネジメントにも、どのような場面でエラーが発生しやすいか予測し、軽減策を考える場合などに利用できる考え方だと思います。
ちなみに、「CRISP-DM」という文字を見たとき、DMは「データマネジメント」の略かと思いましたが、さすがに違いました(^_^;)